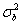 : the between-subjects
component--the extent to which subjects vary when all measurements are
made without error.
: the between-subjects
component--the extent to which subjects vary when all measurements are
made without error.
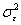 : the within-subjects
component--pure measurement error, the extent to which a single subject's
repeated measurements vary.
: the within-subjects
component--pure measurement error, the extent to which a single subject's
repeated measurements vary. SAMPLE SIZE CALCULATIONS
Group Randomized, Multi-level, Hierarchical,...whatever
It is becoming increasingly common for experiments to use designs that involve analytic methods other than those for simple random sampling. The typically involve some form of clustering. For example,
The name for these designs varies according to the area of application. Some of the names that have been used are group randomized studies, hierarchical studies, and multi-level studies.
In general, a proper analysis will be equivalent to the appropriate averaging over all elementary units that are part of a randomization unit. For example,
Sample size estimates are calculated in the same way as for comparing independent or paired samples, but paying particular attention to the variability of the response.
Example
Consider a cross-sectional study of the effect of two behaviors on bone loss. Bone density measurements are subject to random measurement error resulting in part from placement. There are two ways to account for this: (1) more subjects measured once or (2) fewer subjects measured many times with repositioning, that is, having the subject get off the table, walk around, and get back on the table.
To implement method (1), we use to SD from data from subjects measured once with the same device we plan to use.
With method two, we need data in which subjects were measured repeatedly with repositioning. We use variance components to assess between and within subject variability.
The variance of a set measurements is composed of two parts
: the between-subjects
component--the extent to which subjects vary when all measurements are
made without error.
: the within-subjects
component--pure measurement error, the extent to which a single subject's
repeated measurements vary. If a subject is measured m times, the variance of the mean of those measurements is
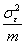
Thus, the variance of a set of bone densities where each is the mean of m measurements made on each subject with repositioning is
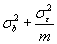
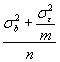 .
. These expressions show the gains to be made from taking repeated
measurements. Suppose, for example, that most of the variability is
between subjects, that is, =
9. Then, the degree of
precision obtained by making one measurement on n subjects
requires (9.5/10)n subjects if two measurements are made on each
subject. This is a mere 5% reduction for doubling the amount of time
with each subject.
However, if the between and within subject variances are the same, the degree of precision obtained by making one measurement on n subjects can be obtained by taking two measurements on (1.5/2)n subjects, that is, with 25% fewer subjects. If three measurements were made on each subject, only (1.33/2)n subjects would be needed--a 33% reduction.
Note that the greatest possible percent reduction, regardless of the number
of measurements per subject, is 100 /(+). When = 9, the greatest
possible reduction is 10%. When =
, the greatest possible reduction
is 50%.
Estimating between and within subject variance
If there is a dataset in which subjects have been measured repeatedly, between and within subject variance can be estimated by using single-factor ANOVA with subject as the study factor. It is straightforward to show that
| Source | Mean Square | Expected Mean Square |
| (Between) Subject | 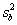 |
n+ |
| (Within Subject) Error | 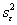 |
|
The method of moments equates the sample and expected mean squares and solves for the population variances, that is,
= n +
=
=
= ( - )/n.
Intra-class Correlation Coefficient
The intra-class correlation coefficient is the proportion of variance due to differences between subjects when they are measured without error. That is,
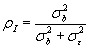 would be 0, and the
intra-class correlation would be 1.
would be 0, and the
intra-class correlation would be 1.
Historically, the intra-class correlation was defined as a particular Pearson correlation coefficient that is close in value to proportion of variance. It is the correlation coefficient for the dataset containing every ordered pairwise combination of each subject's data. For example, if a subject is measured 3 times--X1, X2, X3--the intra-class correlation would be calculated from the dataset containing (X1,X2), (X2,X1), (X1,X3), (X3,X1), (X2,X3), (X3,X2).
[back to LHSP]